Maybe you have heared about the Chaos Monkey and later the Simian Army that Netflix introduced to check the resiliency of their AWS systems. These tools are part of a concept called Chaos Engineering. The principle behind Chaos Engineering is a very simply one: since your software is likely to encounter hostile conditions in the wild, why not introduce those conditions while (and when) you can control them, and then deal with the fallout then, instead of at 3am on a Sunday.
Azure Chaos Studio
Time to introduce Azure Chaos Studio, a managed service that uses chaos engineering to help you measure, understand, and improve your cloud application and service resilience.
With Chaos Studio, you can orchestrate safe, controlled fault injection on your Azure resources. Chaos experiments are the core of Chaos Studio. A chaos experiment describes the faults to run and the resources to run against. You can organize faults to run in parallel or sequence, depending on your needs.
Let’s give Azure Chaos Studio a try and create our first chaos experiment…
- Go to the Azure Chaos Studio product page and click on Try Chaos Studio.
- You’ll be redirect to the Azure Portal and after logging in you should see the following:
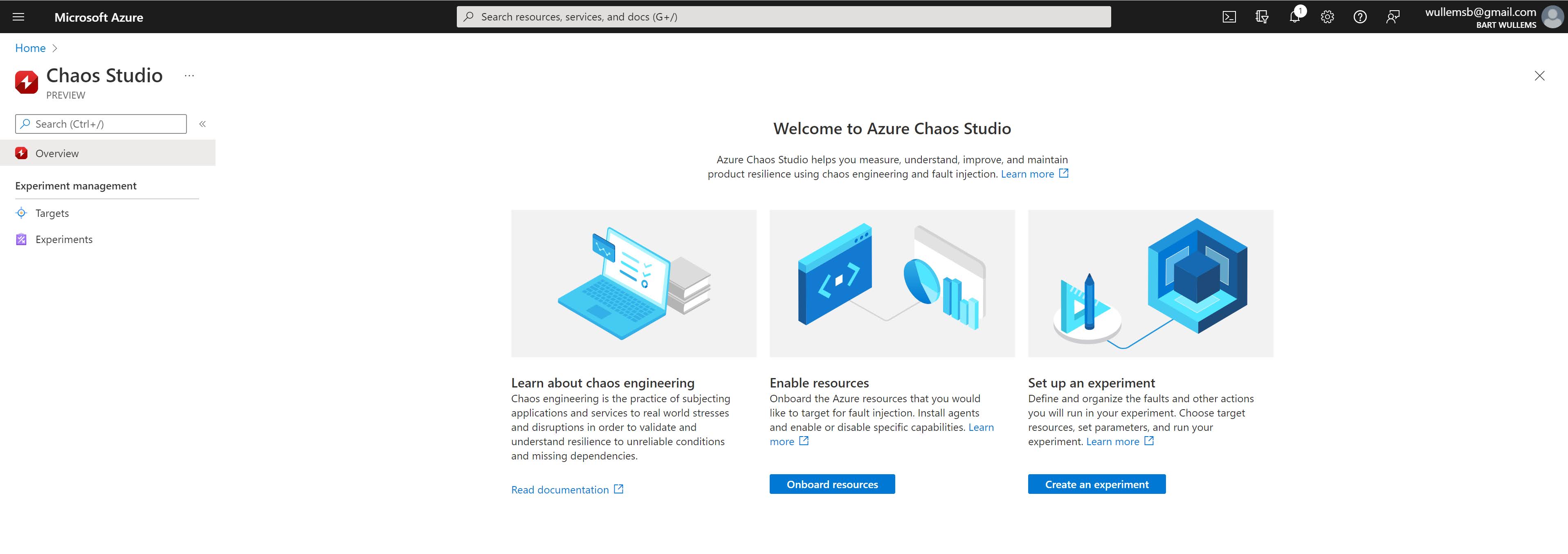
Onboard a resource as a Chaos target
- The first step is to select a target. Before we can target a specific resource, we first need to onboard this resource in Azure Chaos Studio. There are 2 possible target types:
- Service-direct faults run directly against an Azure resource, without any installation or instrumentation. Examples include rebooting an Azure Cache for Redis cluster, or adding network latency to Azure Kubernetes Service (AKS) pods.
- Agent-based faults run in VMs or virtual machine scale sets to do in-guest failures. Examples include applying virtual memory pressure or killing a process.
- Put a checkbox next to the resource(s) you want to onboard.

- Now click on Enable targets then Enable service-direct targets from the dropdown menu.

- This will trigger a new deployment and update the target resource(s).
- After the resource deployment has completed succesfully, we can set the capabilities that should be supported on the target. This can be controlled through Manage Actions.

- In our example, we have enable only the service-direct target type for the VM. This gives us only one capability; Cloud Service Shutdown.

Create our first chaos experiment
- Now that we have onboarded a resource, it is finally time to create our chaos experiment.
- Click on Experiments and click on Create.

- Fill in the Subscription, Resource Group, and Location where you want to deploy the chaos experiment. Give your experiment a Name. Continue by clicking on Next : Experiment designer >

- In the Experiment designer we can specify the different steps and actions that should be taken. In this example, we keep it simple and only use one step and one branch. We click on Add action.
- Now we can specify the fault that should be triggered and some extra related parameters depending on the chosen fault type. We choose Cloud Service Shutdown as this was the only capability that was supported by our target. Click on Next: Target Resources > to continue.

- Select the target resource and click on Add.

- Click on Review + Create to move to the last step.

- Click on Create to complete the process.
- Notice the remark. We need to assign the experiment identity to our resource before we can run the experiment.

Assign the experiment identity to our target resource
- Go to our target resource in the Azure portal.
- Go to Acces Control (IAM) and click Add – Add Role Assignment.

- Select the correct role (we are lazy and use the Owner role) and click on Next.
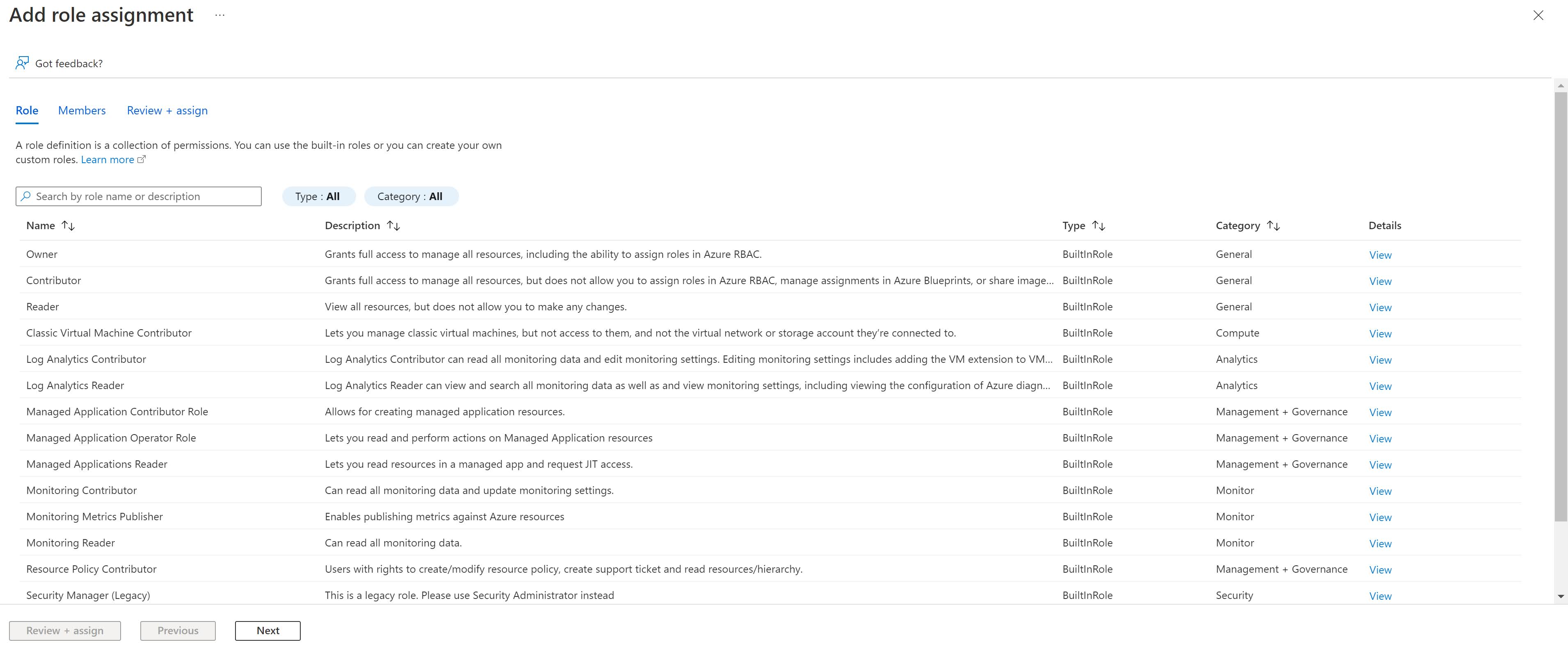
- Click on Select Members and search for the experiment name

- Click Review + assign then Review + assign.
Run the experiment
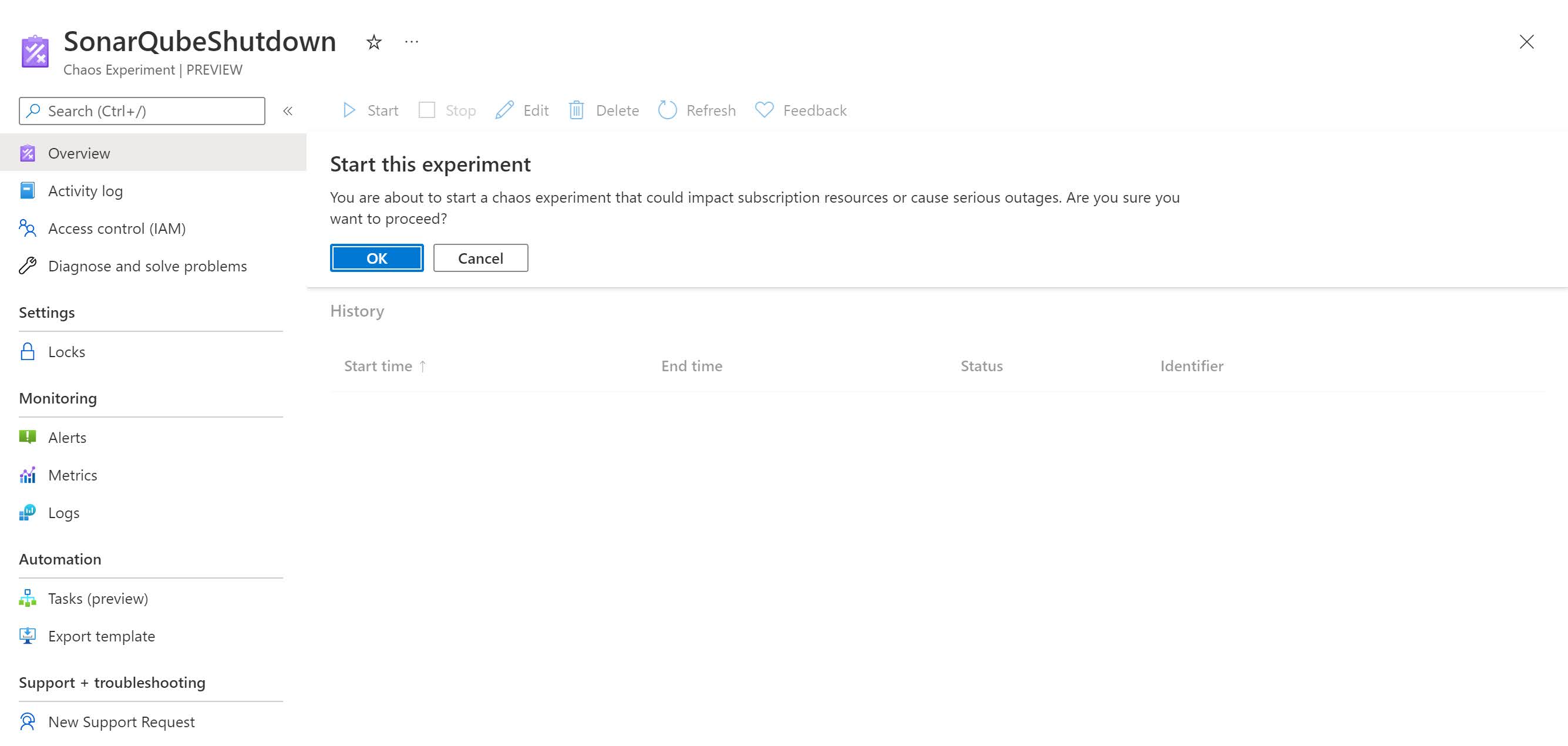
- In the Experiments view, click on our experiment, and click Start, then click OK.
Learn more
If you want to learn more, check out this episode of Azure Friday: